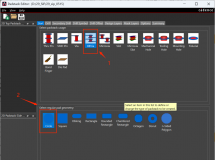
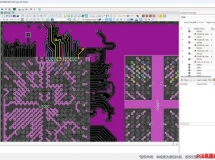
|
22| 0

零基础实操把知识库接到聆思CSK6大模型开发板上 |

| ||
 /1
/1 












Copyright ©2015-2022 长沙市凡亿教育科技有限公司 Powered by©Discuz! 技术支持:凡亿教育 ( 湘ICP备2024059722号 )



 窥视卡
窥视卡
.png")

 置顶卡
置顶卡 变色卡
变色卡